遺伝子発現の流れ
生物の遺伝情報はDNAに保存されていますが、DNAだけでは何の働きもできません。真核生物の細胞では、核の中にDNAがコンパクトに収納されています。このDNAから必要な情報をRNAに写し取り、それを核外に運んで色々な分子装置を使ってタンパク質が作られています。「遺伝情報がDNAからRNAを経てタンパク質へと流れる」という概念を分子生物学ではセントラルドグマといいます。
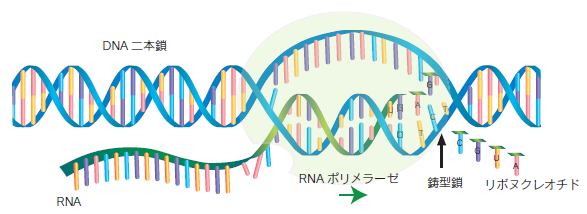
DNAからRNAへ「転写」
細胞が、DNAをRNAに写しとる仕組みを「転写」と呼びます。RNAはDNAと同じ核酸ですが、DNAとは構造的に2つの違いがあります。1つ目は、RNAの糖(リボース)は、酸素分子がDNAの糖(デオキシリボース)より一つ多いことです。そのため、RNAはDNAに比べて立体構造を取りやすくなっており、細胞内では一本鎖のまま存在しています。2つ目は塩基にチミン(T)がなくウラシル(U)があることです。ウラシルはDNAのアデニンと水素結合で対合します。
ヌクレオチドの基本構造
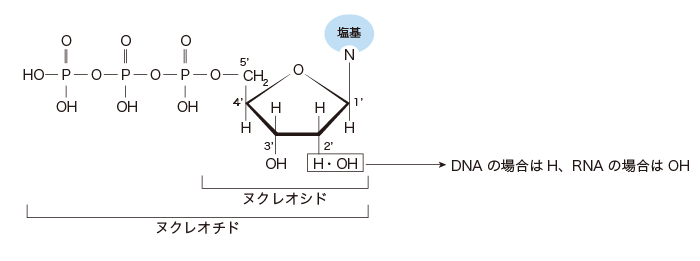
RNAでは糖の特定の場所に水酸基(-OH)が結合していますが、DNAでは酸素Oが抜け(=デオキシ)、
水素(-H)が結合しています。
転写では、RNAポリメラーゼという酵素によってDNAからRNAが作られます。まず、DNAの遺伝情報を保存している領域の5'側(上流)に存在する転写を調節する領域(プロモーター領域)に、RNAポリメラーゼが結合します。次にRNAポリメラーゼは、プロモーター領域の3'側(下流)へ連続的に移動しながら、10塩基対ほどの長さのDNAを二重らせんが開いた状態にし、ペアのいないDNA(sense鎖)に対応するRNA塩基(A、U、G、Cのどれか)を運んで塩基対を形成させ、DNAの塩基配列を相補的に写し取ったRNAを合成します。
このとき、合成されたRNAはタンパク質を合成する“指令”を写し取ったRNAであり、メッセンジャーRNA(mRNA)と呼ばれます。真核生物には3種類のRNAポリメラーゼが存在し、それぞれ役割の異なるRNAを合成しています。mRNAはRNAポリメラーゼⅡによって合成されます。
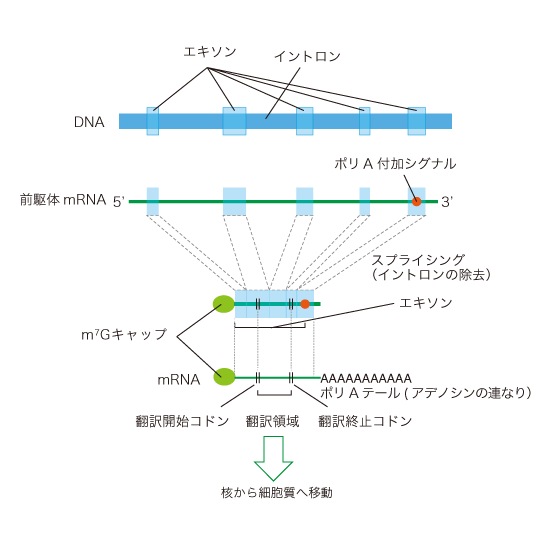
DNAから転写されたmRNAはタンパク質設計に関する部分(エキソン)とタンパク質設計に不要な部分(イントロン)を持っています。mRNAからイントロンを除去し、エキソンを繋ぎ合わせる過程を「スプライシング」といいます。また、mRNAの5’末端に5’-Capとよばれるメチル化されたGTPが付加されることで、リボソームに結合しやすくなり、リボヌクレアーゼによる分解を防ぐことができます。3’末端には100〜300個のアデニン塩基が付加され(ポリAテール)、mRNAが核の外へ出て行く手助けをします。さらに、mRNAの一部の塩基は核内で修飾を受け(参照:RNA修飾とは?)、RNA結合タンパク質に導かれて核膜孔から核外に出ていきます。
スプライシング
RNAからタンパク質へ「翻訳」
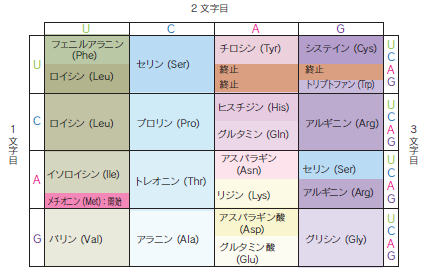
mRNAが持っているのは、AUGCという4種類の塩基の配列情報です。一方、タンパク質を構成しているアミノ酸は20種類あります。そのため、3個1組の塩基(コドン)でアミノ酸1個を指定します。塩基は4種類ありますので、3個の塩基を組み合わせると4x4x4=64通りの組み合わせがあり、20種類のアミノ酸全てに対応できます。1種類のアミノ酸に1種類のコドンが対応している訳ではなく、1個のアミノ酸を指定するコドンは、1〜6種類です。さらにコドンには開始コドンと終止コドンが存在します。開始コドン(AUG)はメチオニンというアミノ酸をDNAのどこから翻訳するのかを決定します。終止コドン(UAA、UAG、UGG)まで来るとその前でアミノ酸の合成は終了します。終止コドンは、指定するアミノ酸を持ちません。翻訳では、開始コドンを起点として、その後、3つ組塩基ずつ1つのコドンとして遺伝情報は読まれます。コドンとアミノ酸の対応(図.遺伝暗号表)は全ての生物で普遍的ではなく、例えば、ヒトのミトコンドリア内では対応するアミノ酸の一部が異なっています。
遺伝暗号表
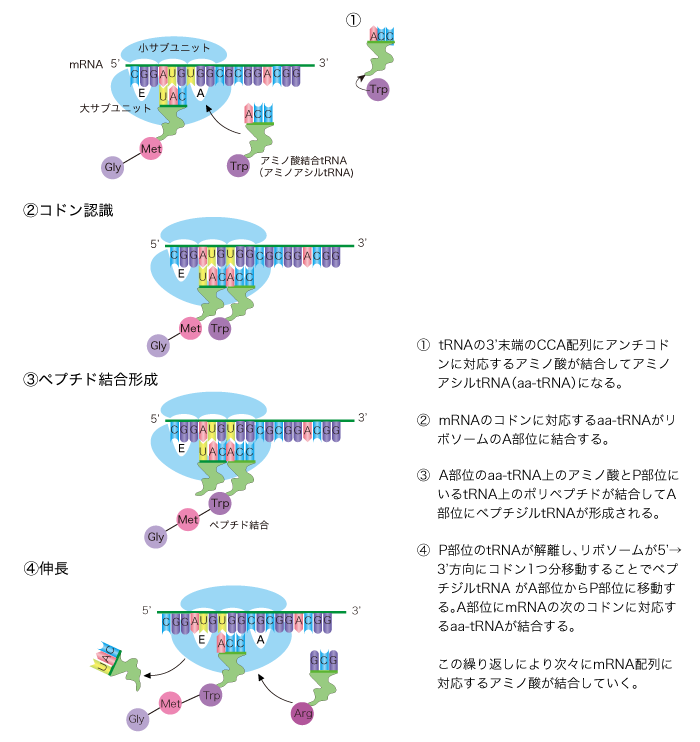
核から細胞質へ輸送されたmRNAに大小2つのサブユニットから構成されるリボソームが結合し、タンパク質が合成される過程を「翻訳」と呼びます。リボソームは巨大なタンパク質−RNA複合体です。リボソームを構成するRNAをリボソームRNA(rRNA)と呼びます。リボソームの大小のサブユニットはタンパク質を合成していないときは分離しています。小サブユニットにmRNAが結合した後、大サブユニットが結合し、大小サブユニットはアミノ酸を結合しながらmRNA上を3'末端方向に移動していきます。アミノ酸同士はペプチド結合でつながれます。順々につながったアミノ酸をポリペプチドと呼びます。伸長したポリペプチドが折りたたまれて立体構造をとり、機能を有してタンパク質として働きます。
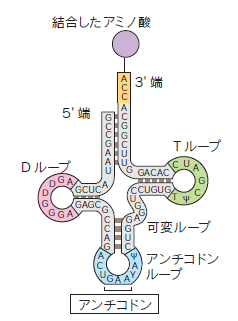 リボソームまで塩基配列に対応したアミノ酸を運ぶ役割を果たすのが、トランスファーRNA(tRNA)です。tRNAの一部にはアンチコドンと呼ばれる3つ組塩基配列があり、mRNAのコドンと対応します。tRNAは、それぞれのアンチコドンに対応するアミノ酸とアミノアシルtRNA合成酵素によって正しく結合させられます。アミノアシルtRNA合成酵素は、20種類あり、アミノ酸、tRNA、ATPという3種類の分子を認識する部位を持っています。tRNAは一本鎖ですが、内部の相補配列で塩基対を形成し、クローバーの葉のような二次構造を持ち、L型の高次構造をとっています。リボソームには、主にrRNAからなるA部位、P部位、E部位と呼ばれるtRNAの結合部位があり、ペプチド結合の触媒部位もタンパク質ではなく、大サブユニットのrRNAからなります。tRNAはアミノ酸が次のアミノ酸に結合されると、リボソームから離れていきます。
リボソームまで塩基配列に対応したアミノ酸を運ぶ役割を果たすのが、トランスファーRNA(tRNA)です。tRNAの一部にはアンチコドンと呼ばれる3つ組塩基配列があり、mRNAのコドンと対応します。tRNAは、それぞれのアンチコドンに対応するアミノ酸とアミノアシルtRNA合成酵素によって正しく結合させられます。アミノアシルtRNA合成酵素は、20種類あり、アミノ酸、tRNA、ATPという3種類の分子を認識する部位を持っています。tRNAは一本鎖ですが、内部の相補配列で塩基対を形成し、クローバーの葉のような二次構造を持ち、L型の高次構造をとっています。リボソームには、主にrRNAからなるA部位、P部位、E部位と呼ばれるtRNAの結合部位があり、ペプチド結合の触媒部位もタンパク質ではなく、大サブユニットのrRNAからなります。tRNAはアミノ酸が次のアミノ酸に結合されると、リボソームから離れていきます。
ポリペプチドの合成
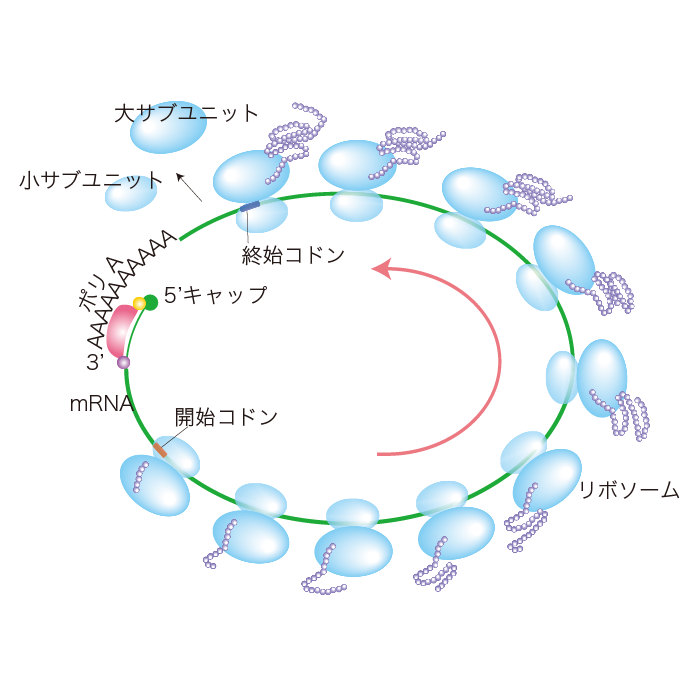
ポリペプチド鎖は、リボソームから離れるときに綺麗に折り畳まれている場合もありますが、ほとんどのタンパク質はリボソームから離れたところで分子シャペロン(分子シャペロンとはタンパク質が正しい構造をとり、正常な機能を発揮できるようにさせるタンパク質です。)と結合して正しく折り畳まれます。タンパク質合成の効率をあげるため、1つのリボソームでの翻訳が進むと、次のリボソームがmRNAに結合し翻訳を始めます。翻訳中のmRNAには多数のリボソームが付いたポリリボソームになっています。真核生物の開始因子は5'末端だけでなく3'末端のポリA配列にもしっかり結合し、環状化します。環状になると翻訳を終えたリボソームの再利用に役立ち効率的です。
ポリリボソーム

ニーレンバーグ「遺伝暗号の解読」
1961年、ニーレンバーグらは、大腸菌を破砕した抽出液にタバコモザイクウイルスのRNAを入れてタンパク質合成を調べていました。そのとき、何も合成されないはずの対照実験としてポリウリジン(U)を入れておいたのですが、予想に反してポリUのチューブからポリフェニルアラニン(Phe)の合成を示す強いシグナルが出たのです。つまり、ポリUはPheをコードすることを発見したのです。彼らは続いてポリCがポリプロリン(Pro)をコードすることも決定しました。その後、多くの人々の研究によって遺伝暗号は3個の塩基で1個のアミノ酸に対応すること、塩基配列は一定の出発点から読まれること、句読点はないことなどが明らかにされ、1966年までに全ての遺伝暗号が解読されました。